

۴ فناوری ساختارشکن در شیوهی مدیریت دارائی با علم دادهها
صنعت خدمات مالی و علیالخصوص شاخهی مدیریت دارائی همواره با حجم بالایی از داده سروکار داشته است. وفور داده، یک مزیت بزرگ به شمار میآید و ارائهی راهکارهای مبتنی بر داده و یادگیری ماشین را تسهیل میکند. دستاندرکاران حوزهی مدیریت دارائی میتوانند از این مزیت برای شخصیسازی خدمات عرضه شده به مشتری، بهبود مدیریت ریسک و فعالسازی سیستم تشخیص کلاهبرداری استفاده کنند.
مدتی است که صندوقهای پوشش ریسک و سایر بازیگران عرصهی خدمات مالی، با موج تحول دیجیتال همراه شده و به تکنولوژیهای مبتنی بر داده روی آوردهاند. گلدمن ساکس (Goldman Sachs)، که یک بانک پیشرو در حوزهی سرمایهگذاری است، در طی ۱۰ سال گذشته، راهکارهای مبتنی بر دادهی بسیاری را به کار گرفته است. پیشبینی آیندهی بازار خرد و تخمین دقیق رشد تولیدی چین، موفقیتهای چشمگیری هستند که در نتیجهی اقدامات این بانک، حاصلشدهاند.


متأسفانه، شرکتهای سنتی مبتنی بر مدیریت ثروت، از قافلهی تحول عقب ماندهاند و هنوز به دنبال راههایی برای داده محور شدن میگردند. بر اساس گزارش کریسیل گلوبال (CRISIL Global)، بیش از ۷۰ درصد مدیران وجوه نیویورک، بزرگ داده (Big Data) را یک سرمایهی مهم در مدیریت دارائی میدانند.
در طول یک دههی گذشته، پیشرفتهای زیادی در تکنولوژی تجزیهوتحلیل داده رخ داده است. الگوریتمهای اولیه، فقط میتوانستند از دادههای ساختاریافته استفاده کنند، ولی راهکارهای مبتنی بر یادگیری ماشین مدرن، قابلیت تجزیهوتحلیل اسناد غیر ساختاریافته را نیز دارند.
تجزیهوتحلیل احساسات و تشخیص تصویر، تکنولوژیهای جدیدی هستند که در راستای شناسایی افتوخیزهای بازار سهام، به کار گرفتهشدهاند. بهعنوانمثال، جمعآوری و تحلیل شایعاتی که در مورد برندهای مختلف مطرح میشوند، تاجران را در پیشبینی قیمت سهام آن شرکتها، یاری میکند.
تاکاشی سوابه (Takashi Suwabe)، مدیر سبد سهام (Portfolio) و استراتژیست سرمایهگذاری کمی در بخش مدیریت دارائی گلدمن ساکس است. او میگوید:
دسترسی به دادههای جدید و ضبط و پردازش سریع آنها، زمینههایی نوین را برای جذب سرمایه فراهم کرده است.
حال بیایید نگاهی به چند عملیات اساسی داشته باشیم که به کمک رویکرد مبتنی بر داده، بهبود مییابند.
۱) شخصیسازی و مشاوران هوشمند، شیوهی تعامل با مشتری در حوزهی مدیریت دارائی را تغییر میدهند
مشتریان، در تمامی صنایع، به شخصیسازی علاقهمندند و مدیریت دارائی نیز از این امر مستثنا نیست. در دنیای امروز، مشاوران هوشمند (و یا مشاوران رباتیک)، پرطرفدارترین روش شخصیسازی هستند. الگوریتمهای مربوطه به بررسی دادههای مختلف مشتری (مانند میزان تحمل ریسک، رفتار، معیارهای قانونی و اولویتها) میپردازند و بر اساس آنها، پیشنهادهای مناسبی را ارائه میکنند.
ترکیب منابع دادهی مختلف، امکان افزایش ابعاد مدلها و حل مسائل پیچیدهی بهینهسازی مربوط به سبد سهام شخصی افراد را فراهم میکند. مدیران سبد سهام، میتوانند از این فرصت استفاده کرده و طرحهای سرمایهگذاری متناسب با هر مشتری را در عملیات کسبوکار به کسبوکار (B2B) و کسبوکار بهمشتری (B2C)، به وی پیشنهاد دهند.
افزایش تعداد مشاوران رباتیک در سال گذشته، حاشیههایی را با خود به همراه داشت. درست است که گسترش عمومی این نوع از مشاوران به این زودیها انجام نخواهد گرفت، ولی روشن است که آیندهی این تکنولوژی درخشان خواهد بود. شرکت ایتی کرنی (AT Kearney)، اعلام کرده:
ارزش دارائیهایی که در سال ۲۰۱۶، توسط مشاوران رباتیک، مدیریت شدند، ۰.۳ تریلیون دلار بوده و این رقم در سال ۲۰۲۰، به ۲.۲ تریلیون دلار خواهد رسید.

مورگان استنلی (Morgan Stanley) و یوبیاس (UBS)، جزو اولین مؤسساتی بودند که در بین سالهای ۲۰۱۳ تا ۲۰۱۵، از مشاوران رباتیک استفاده کردند. مورگان استنلی، آغازگر ثریدی اینسایتس (۳D Insights) بود و ابزاری را عرضه کرد که کار دستهبندی، تجزیهوتحلیل و انتخاب دادههای موجود در گزارشات را انجام میدهد، در نتیجه، مشاوران میتوانند در کوتاهترین زمان ممکن به اطلاعات مورد نیازشان دسترسی پیدا کنند. یوبیاس، یک گام فراتر گذاشت. این شرکت، یوبیاس ادوایس (UBS Advice) را راهاندازی کرد که تحلیل آنی تصمیمات استراتژیک را در سطح ریاست امور سرمایهگذاری (CIO) انجام میدهد و مشاوران میتوانند از طریق این تحلیلها، پیشنهادات مناسب با هر مشتری را در اختیار او قرار دهند. تعدادی از شرکتهای ولثتک، مانند وایزبانیان (WiseBanyan)، بترمنت (Betterment) و ثیرد فایننشیال (Third Financial) نیز دستی بر آتش شخصیسازی و مشاورهی رباتیک داشتهاند.

مشاوران هوشمند،با یک تیر، دو نشان میزنند: کسب اطمینان از حس رضایت مشتری و طراحی دیدگاههای برنامهریزی مالی بر اساس رفتار مشتری. مدیران میتوانند پیشبینی دقیقتری از جریان نقدی ورودی و خروجی داشته باشند.
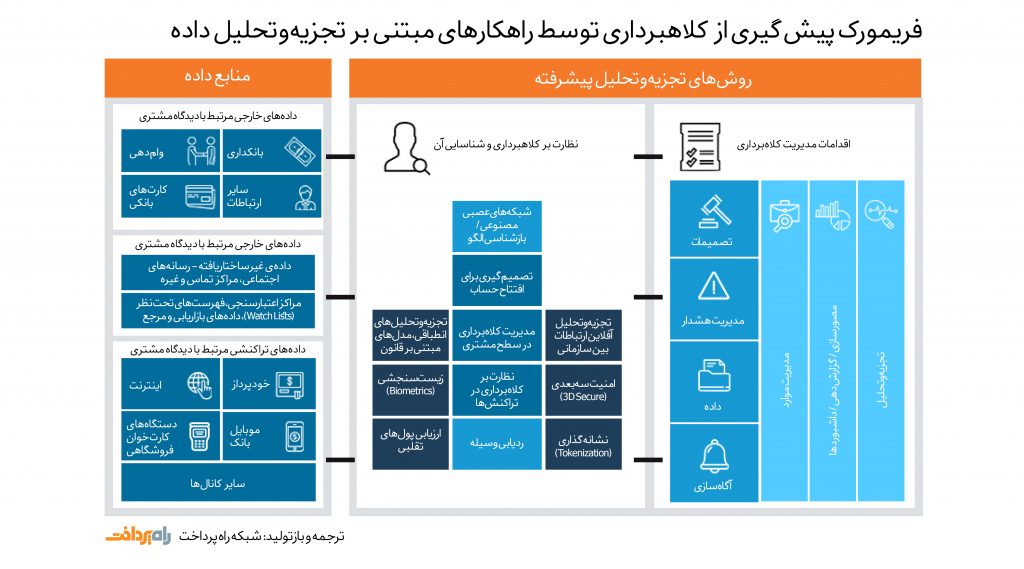
۲) تشخیص کلاهبرداری با استفاده از شبکههای عصبی
مدلهای مبارزه با پولشویی و سیستمهای تشخیص کلاهبرداری، یکی از تکنولوژیهای نوظهور هستند و کمک زیادی به شناسایی فعالیتهای مشکوک میکنند. این سیستمها، بهگونهای تعلیم دادهشدهاند که رفتار تکتک اشخاص را در فرآیند مدیریت سرمایه، تحت ارزیابی قرار دهند. شیوهی کار این سیستمها چگونه است؟
روش متداولی که برای شناسایی فعالیتهای کلاهبردارانه به کار گرفته میشود، شبکههای عصبی عمیق است؛ این شبکهها، تمامی دادههای ساختاریافته و ساختارنیافته، از قبیل فایلهای پیدیاف، فعالیتهای شبکههای اجتماعی، سوابق مدیریت ارتباط با مشتری (CRM) و سایر فعالیتهای تحت وب را تحلیل میکنند. شبکههای عصبی در شناسایی ارتباط موجود در نوع رفتار مشتری (و یا کارمند) با احتمال انجام تقلب توسط وی، بسیار قوی هستند.
به عنوان نمونه، روش کاپژمینی (Capgemini) در شناسایی تقلب، دستاوردهای زیر را به همراه داشته است:
- ۵۰ -۹۰ درصد افزایش در آشکارسازی کلاهبرداریها
- تا ۹۰ درصد بهبود دقت در تشخیص تقلب
- کاهش زمان بررسی تا ۷۰ درصد
- تشخیص آنی کلاهبرداری
- عملکرد شبکهی عصبی را میتوان از طریق ورود دادههای جدید و بررسی تشخیصهای موفق و ناموفق و یادگیری بهبود بخشید.
۳) تجزیهوتحلیلهای پیشگویانه، کارایی شرکتهای سرمایهگذاری را افزایش میدهند
کارایی شرکتهای سرمایهگذاری، رابطهی مستقیمی با پیشبینی آیندهی بازار ثروت دارد. سهام، اوراق قرضه، انتخابها و معاملات آتی، میلیاردها رکورد تجاری را در طول یک روز، تولید میکنند. تمامی این دادهها، به شکل سریهای زمانی نامانا هستند، بطوریکه تغییرات فصلی و روندها، تأثیر مستقیمی بر آنها ندارند و همین موضوع، پیشبینی آنها را دشوار کرده است. روشهای آماری متداول، دقت و سرعت لازم را در پیشبینی رکوردهای نامانا ندارند و تحلیلگران مالی با مشکل پیچیدهای مواجه شدهاند. اخیراً، مشخص شده که روشهای مبتنی بر یادگیری ماشین، توانایی مقابله با پدیدهی نامانایی در دادههای سری زمانی را دارند. بهطور خلاصه میتوان گفت: سه رویکرد اساسی وجود دارد.
- روشهای سنتی یادگیری ماشین: آموزش دادهها و پیشبینی آینده، توسط دادههای کوتاهمدت انجام میشود.
- یادگیری جریانی: مدل پیشبینی موجود، همواره توسط دادههای جدید بهروز میشود، مزیت این روش، داشتن دقت بالا در محیط متغیر بازار است.
- مدلهای گروهی: مدلهای متعدد یادگیری ماشین، با نقاط قوت و ضعفی که دارند، کار تحلیل دادههای ورودی را انجام میدهند و پیشبینیها بر اساس نتایج تلفیقی، انجام میشوند.
پردازش زبان طبیعی (Natural language processing) و تجزیهوتحلیل احساسات در رسانههای اجتماعی، بخش دیگری از علم داده هستند. این روشها، از طریق تجزیهوتحلیل پستها و توئیتهایی که در رابطه با برندهای مختلف به اشتراک گذاشتهشدهاند؛ فرآیند پیشبینی را انجام میدهند. با این روش، مدیران ثروت میتوانند به شکلی فعالانه، محصولات محبوب را شناسایی کرده و قبل از بالا رفتن قیمت سهام شرکت تولیدکنندهی آن، سرمایهگذاری خود را انجام دهند. از طرف دیگر، همین مدیران ثروت، اگر شاهد نارضایتی عمومی از شرکتی باشند که در آن سرمایهگذاری کردهاند، میتوانند به سرعت اقدام کنند و قبل از آنکه این نارضایتی، تأثیری در بازار بورس بگذارد، سرمایهی خود را از این شرکت بیرون بکشند.
اگر میخواهید با یک نمونهی موفق از شرکتهایی که این نوع پیشبینی را انجام میدهند، آشنا شوید، ما کریمسون هگزاگون (Crimson Hexagon) را پیشنهاد میکنیم. این شرکت خدمات تجزیهوتحلیل داده را ارائه میدهد و با هدف پیشبینی قیمت سهام، حدود یک تریلیون رکورد را از توییتر، تامبلر و فیسبوک جمعآوری کرده است. استفانی نیوبای (Stephanie Newby)، مدیرعامل کریمسون هگزاگون است. او میگوید: قبل از اوجگیری اعتراضات اینترنتی نسبت به گوشی تلفن همراه سامسونگ نوت ۷، توانسته سقوط قیمت سهام این شرکت الکترونیکی را پیشبینی کند. در چند روز اولیهی عرضهی گوشی تلفن همراه سامسونگ نوت ۷، نارضایتیها در رابطه با منفجرشدن این گوشیها، چندان علنی نشده بودند. این مقام رسمی معتقد است که اگر سرمایهگذاران، سهام خود را در زمان مناسب فروخته بودند، سود زیادی میبردند.
۴) تجزیهوتحلیل مبتنی بر سناریو، به بهبود مدیریت ریسک در شرکتهای فعال حوزهی ثروت، کمک میکند
مدیریت ریسک، بخش مهمی از مدیریت دارائی است و مدیریت ریسک ناشی از نوسانات، اهمیتی دوچندان دارد. داشتن عملکرد ضعیف، هم برای مدیران سبد محصول و هم برای مشتریان، زیانآور است؛ بطوریکه اولی، دستمزد خود را از دست میدهد و دومی، پولش را.
یکی از روش سنتی ارزیابی ریسک، محاسبهی انحراف معیار قیمت سهام، در محیط اکسل است. علیرغم آنکه این روش، به شکل گستردهای مورد استفاده قرار میگیرد، ولی قادر به شناسایی تمامی متغیرهای بازار نیست و دیدگاه روشنی نسبت به ریسک، ارائه نمیکند.
رشد قدرت محاسباتی و بستههای جدید پردازش داده، ابزارهای جدیدی هستند که امکان مدلسازی استرس برای شرکتها و بازار سهام را ایجاد کردهاند. امروزه، شما میتوانید میلیونها سناریو را در مورد شرایط ویژهی بازار، مورد آزمایش و ارزیابی قرار دهید. این امر، پیشبینی و تحلیل رویدادهای خاص را میسر میکند.
مدل مونتی کارلو (Monte Carlo)، یک الگوریتم محاسباتی است که از نمونهگیری تصادفی برای محاسبه نتایج استفاده میکند. شبیهسازی پدیدههایی که عدم قطعیت زیادی در ورودیهای آنها وجود دارد، توسط این مدل قابل شبیهسازی هستند و محاسبه ریسک نیز یکی از همین پدیدههاست. شاخصهای مالی و اقتصاد کلان، قیمت سهام و حتی رفتار مشتری، در یک آزمایش ریسک مبتنی بر سناریو، قابلپردازش هستند. اگر مدیران سبد سهام از این امکانات استفاده کنند، بهراحتی میتوانند احتمال پیروزی و شکست را پیشبینی کنند و عملکرد شرکت را بهبود ببخشند.
چگونه استراتژی دادهمحور خود را شروع کنیم؟
پیشتر اشاره شد که بازیگران پیشرو ازجمله گلدمن ساکس، از حدود ۱۰ سال پیش نسبت به پیادهسازی دانش داده در مدیریت دارائی اقدام کردهاند و رقابت رو به رشدی در این حوزه وجود دارد. بحث بر سر این است که چگونه میتوان با سرعت هر چه تمام، در مسیر بهکارگیری دانش داده، حرکت کرد؟
در ادامهی مطلب، ۶ گام کلیدی برای داشتن آغازی درخشان در استراتژی داده، معرفی شده است.
۱) تعیین مشکل و تطبیق آن با فرصتها
مشکلات دردسرساز را شناسایی کنید. آنها را در یک فهرست بنویسید، مهمترینشان را گلچین کنید و آنها را با فرصتهای موجود تطبیق دهید. یک روش عالی برای تبدیل کردن ایده به نقشهی راه، مطرح کردن این ابتکارات با کارکنان اصلی شرکت است. در این شرایط است که نوع دادهی موردنیاز و راهکار مناسب برای حل مشکل، تعیین میشود.
۲) ارزیابی دادهها
مطمئناً، دادهی موردنیاز برای حل مشکل شما، وجود دارد و چالش اصلی این است که چگونه میتوان آن را به یک مجموعهی دادهی سازگار با امال (ML)، تبدیل کرد. آمادهسازی مجموعهی داده، یک مرحلهی حیاتی در عملیات دانش داده است. بهاحتمالزیاد، در مسیر پردازش دادهی خام، به کمک یک متخصص دانش داده نیاز پیدا کنید؛ ولی توصیههای سادهای وجود دارند که با عمل کردن به آنها، لزومی به استخدام این عنوان شغلی نخواهد بود. گام اولیه، باید بهگونهای برداشته شود که نیاز چندانی به جمعآوری دادههای اضافی وجود نداشته نباشد.
۳) استفاده از استعدادهای کارآمد
انجام این پروژه، به دو صورت امکانپذیر است: استفاده از تیم داخلی و یا همکاری با تیم مشاورهی خارجی. استخدام و آموزش یک تیم علم دادهی داخلی، فرآیندی پرهزینه و زمانبر است، ولی امنیت دادهها را تضمین میکند. از سوی دیگر، همکاری با یک تیم کارشناسی موثق خارجی در حوزهی تکنولوژی عمیق و تخصص دامنه، پردازش، آمادهسازی و تنظیم زیرساختها را تسهیل میکند.
۴) توسعهی مدلها و آمادهسازی زیرساختها
مدلسازی و آزمایش، مستلزم بهکارگیری و ارزیابی روشهای مختلف یادگیری ماشین و انتخاب دقیقترین آنهاست. پردازش مجموعهی دادهها و آموزش مدلها را میتوان در لپتاپهای اداری انجام داد. زمانی که نسخهی نهایی مدل شما آماده میشود و با جریان دادههای آنی مواجه میشود، ممکن است اختلالاتی به وجود بیاید. برای پردازش دادهها، دو گزینه وجود دارد: راهکار اول، استفاده از سرور داخلی و راهکار دوم، بهکارگیری ابزارهای محاسبات ابری، مانند آژور (Azure)، گوگل کلاود (Google Cloud) و آمازون (Amazon) است. نیاز به تعمیر و نگهداری دورهای سرور، یکی از معایب راهکار اول به شمار میرود.
۵) یکپارچهسازی راهکارها با زیرساختهای فناوری اطلاعات و ارتباطات
هماهنگسازی راهکارهای تحلیلی با هدف کاری موردنظر شما، مستلزم اتصال اجزا از طریق ایپیآی (API)ها و تنظیم عناصر واسط بوده و نیروی کار مهندسی بیشتری را میطلبد. بهعنوانمثال، ممکن است شما بخواهید در میان مدیرانی که محیط وب را اداره میکنند و تخصیص دارائی را انجام میدهند، طرح شناسایی کلاهبرداری را اجرا کنید؛ این طرح، نیازمند پیادهسازی سطح جدیدی از پیگیری تعاملات است. کپی و پیست عملیات، تجزیهوتحلیل رفتارهای عادی و غیرعادی، نمونههایی از همین پیگیریها هستند.
۶) آموزش دانش و مهارت به کارکنان
اگر میخواهید که کارمندانتان با تحلیلهای ردیابی جدید آشنا شوند، باید افرادی را برای آموزش آنها بکار بگیرید و زمان مناسبی را برای این کار اختصاص دهید. اگر این کار را نکنید، تمامی نرمافزارهای گرانقیمت و پیچیده، هیچ کاربردی برای کارکنان نخواهند داشت. در مرحلهی نهایی، علاوه بر آموزش، باید به بحث تغییر فرهنگ سازمانی نیز پرداخت. یک چالش بزرگ در مسیر تصمیمگیری مبتنی بر داده وجود دارد و آن، این است که: مدیرانی که تاکنون، از تجربهی خود برای اتخاذ تصمیم مناسب استفاده میکردند، بهراحتی نمیتوانند توصیههای مبتنی بر داده را قبول کنند. راهکارهای مبتنی بر یادگیری ماشین، به روابط پنهان بین دادهها پی میبرند ولی مغز انسانها، توانایی تشخیص این روابط را ندارند؛ اینجاست که این عدم پذیرش، خودش را بیشتر نشان میدهد. میتوان نتیجه گرفت: پذیرش تغییر، بهاندازهی خود تغییر اهمیت دارد.
سخن پایانی
اکثریت سازمانهای مدیریت ثروت، در بهکارگیری تکنولوژیهای مبتنی بر داده ضعیف عمل کردهاند. رهبران پیشروی صنعت مالی، حدود یک دههی قبل نسبت به پیادهسازی علم داده در کسبوکارشان، اقدام کردند و امروز، به نظر میرسد که زمان مناسب برای سایر بازیگران این عرصه، فرا رسیده است.
مشاورهی رباتیک و شخصیسازی، جذابترین موارد استفادهی علم داده در مدیریت ثروت هستند. این نوع از تکنولوژیها، توجهات را بهسوی تجزیهوتحلیل احساسات، پیشبینی سریهای زمانی مبتنی بر امال و مدلسازی سناریو محور جلب میکنند. ازآنجاییکه ولثتک، در پذیرش و بهکارگیری دانش داده، از همتایانش عقب افتاده، اکنون باید هوشمندانهتر عمل کرده و تعامل سازندهای با استارتآپهای فینتک و مشاوران تکنولوژی داشته باشد.
منبع: Chatbotslife

